前言
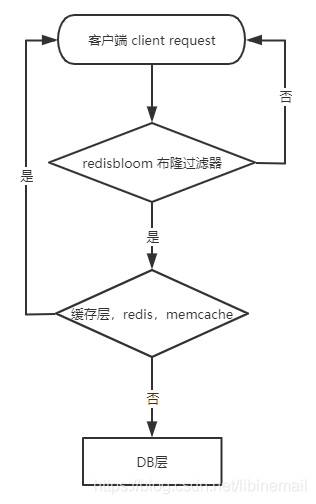
1、原本有10亿个号码,现在又来了10万个号码,要快速准确判断这10万个号码是否在10亿个号码库中?
办法一:将10亿个号码存入数据库中,进行数据库查询,准确性有了,但是速度会比较慢。
办法二:将10亿号码放入内存中,比如Redis缓存中,这里我们算一下占用内存大小:10亿*8字节=8GB,通过内存查询,准确性和速度都有了,但是大约8gb的内存空间,挺浪费内存空间的。
2、接触过爬虫的,应该有这么一个需求,需要爬虫的网站千千万万,对于一个新的网站url,我们如何判断这个url我们是否已经爬过了?解决办法还是上面的两种,很显然,都不太好。
3、同理还有垃圾邮箱的过滤。
那么对于类似这种,大数据量集合,如何准确快速的判断某个数据是否在大数据量集合中,并且不占用内存,布隆过滤器应运而生了。
相关链接
Bloom Filter原理
布隆过滤器是一个基于m位的比特向量(b1,b2…,bm),这些比特向量的初始值为0。同时还有一系列的哈希函数(h1,h2…,hk),这些哈希函数运算后的哈希值范围在[1, m]内。
如下图,就是 x、y、z 三个元素插入到布隆过滤器中,并判断w值是否在集合中的示意图。
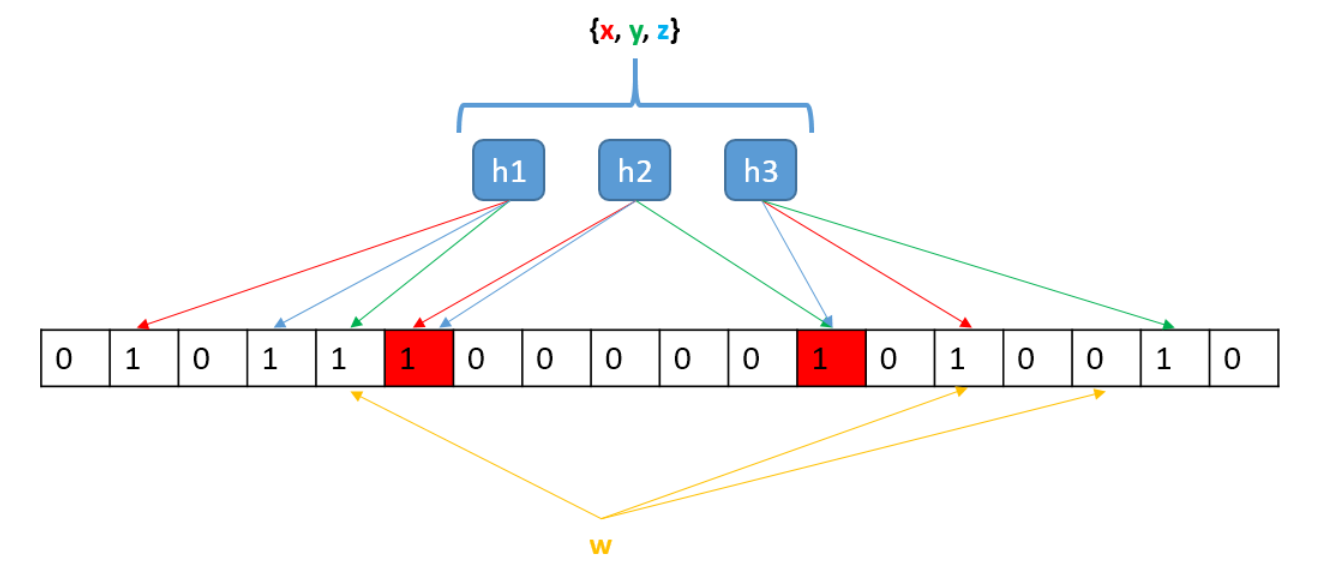 上图中,m=18,k=3
上图中,m=18,k=3
h1、h2、h3 是三个哈希函数将输入值分别映射成比特向量上的某个位置上。
1、数据结构
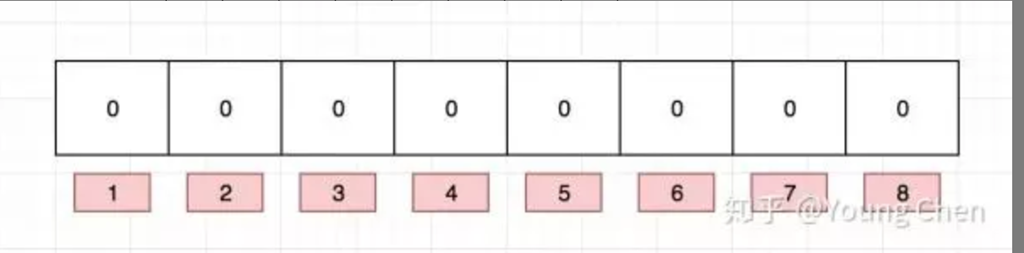
布隆过滤器:一种数据结构,是由一串很长的二进制向量组成,可以将其看成一个二进制数组。
既然是二进制,那么里面存放的不是0,就是1,但是初始默认值都是0。
2、哈希映射
1、布隆需要记录见过的数据,这里的记录需要通过hash函数对数据进行hash操作,得到数组下标并存储在BIT 数组里记为1。这样的记录一个数据只占用1BIT空间
2、判断是否存在时:给布隆过滤器一个数据,进行hash得到下标,从BIT数组里取数据如果是1 则说明数据存在,如果是0 说明不存在
3、精确度
hash算法存在碰撞的可能,所以不同的数据可能hash为一个下标数据,
故为了提高精确度就需要 使用多个hash 算法标记一个数据,和增大BIT数组的大小
假阳子性问题,布隆过滤器判断为数据存在可能数据并不存在,但是如果判断为数据不存在那么数据就一定是不存在的。
4、不支持删除
布隆过滤器只能插入数据判断是否存在,不能删除,而且只能保证【不存在】判断绝对准确
以上不难看出如果给数组的每个BIT位上加一个计数器,插入的时候+1 删除的时候 –1 就可以实现删除。
但是加计数器的实现是有问题的:
由于hash碰撞问题,布隆过滤器不能准确判断数据是否存在,就不能随意删除。其次计数器的回绕问题也需要考虑。
5、布隆过滤器优缺点
优点:
优点很明显,二进制组成的数组,占用内存极少,并且插入和查询速度都足够快。
缺点:
随着数据的增加,误判率会增加;还有无法判断数据一定存在;另外还有一个重要缺点,无法删除数据。
问题
1、hash碰撞
原因:不同的数据可能hash为一个下标数据
解决:
1.1、使用多个 hash 标记一个key
1.2、增大 bit 数组的大小
2、假阳子性问题
原因:
如上图所示,使用哈希函数将每个元素映射到一个二进制向量的三个位上。将集合中每个元素对应的三个位记录成1。
当需要判断一个新的元素w 在不在集合中时,可以先计算出w的三个位,然后只要发现其中存在任何一个位为0, 则可以100%肯定,w不在此集合中。
解决:
2.1、使用多个 hash 标记一个key
2.2、增大 byte 数组的大小
布隆过滤器相关扩展
Counting filters
基本的布隆过滤器不支持删除(Deletion)操作,但是 Counting filters 提供了一种可以不用重新构建布隆过滤器但却支持元素删除操作的方法。在Counting filters中原来的位数组中的每一位由 bit 扩展为 n-bit 计数器,实际上,基本的布隆过滤器可以看作是只有一位的计数器的Counting filters。原来的插入操作也被扩展为把 n-bit 的位计数器加1,查找操作即检查位数组非零即可,而删除操作定义为把位数组的相应位减1,但是该方法也有位的算术溢出问题,即某一位在多次删除操作后可能变成负值,所以位数组大小 m 需要充分大。另外一个问题是Counting filters不具备伸缩性,由于Counting filters不能扩展,所以需要保存的最大的元素个数需要提前知道。否则一旦插入的元素个数超过了位数组的容量,false positive的发生概率将会急剧增加。当然也有人提出了一种基于 D-left Hash 方法实现支持删除操作的布隆过滤器,同时空间效率也比Counting filters高。
Data synchronization
Byers等人提出了使用布隆过滤器近似数据同步。
Bloomier filters
Chazelle 等人提出了一个通用的布隆过滤器,该布隆过滤器可以将某一值与每个已经插入的元素关联起来,并实现了一个关联数组Map[10]。与普通的布隆过滤器一样,Chazelle实现的布隆过滤器也可以达到较低的空间消耗,但同时也会产生false positive,不过,在Bloomier filter中,某 key 如果不在 map 中,false positive在会返回时会被定义出的。该Map 结构不会返回与 key 相关的在 map 中的错误的值。
布隆过滤器安装
1、下载:
地址:https://github.com/RedisBloom/RedisBloom
1 | 下载ZIP 文件,上传到linux |
2、解压编译
1 | 命令: |
3、启动redis 时加载该模块
1 | 两个办法 |
4、redis重新启动
1 | # 杀死redis进程 |
5、测试是否安装成功
1 | 127.0.0.1:6379> bf.add mym meituan |
基本命令
1 | bf.add 添加元素到布隆过滤器,bf.add只能添加一个 |
例子:
1 | > bf.add rurl www.baidu.com |