参考资料
作者搭建记录:https://github.com/mailjobblog/dev_redis/tree/master/master_slave
redis中国区文档:http://redis.cn/topics/replication.html
redis-GitHub(可下载redis.conf和sentinel.conf):https://github.com/redis/redis
redis 官网配置文件:https://redis.io/topics/config
优秀文章:https://www.cnblogs.com/kismetv/p/9236731.html
如何搭建
搭建命令
1 | 需要注意,主从复制的开启,完全是在从节点发起的;不需要我们在主节点做任何事情。 |
实现原理
全量同步
Redis全量复制一般发生在Slave初始化阶段,这时Slave需要将Master上的所有数据都复制一份。具体步骤如下:
1)从服务器连接主服务器,发送SYNC命令;
2)主服务器接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令;
3)主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令;
4)从服务器收到快照文件后丢弃所有旧数据,载入收到的快照;
5)主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令;
6)从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令;
完成上面几个步骤后就完成了从服务器数据初始化的所有操作,从服务器此时可以接收来自用户的读请求。
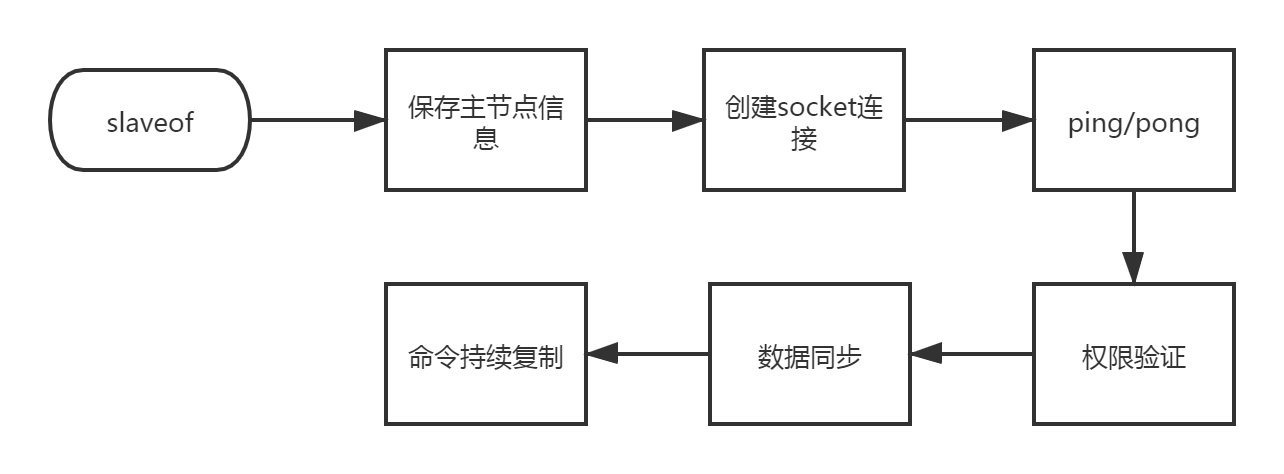
增量同步演示步骤
1、从节点执行slaveof 主节点host 主节点port命令后,在redis会打印如下所示的日志信息:
1 | * REPLICAOF 192.168.216.129:6379 enabled (user request from 'id=4 addr=127.0.0.1:58476 fd=9 name= age=142 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=49 qbuf-free=32719 argv-mem=26 obl=0 oll=0 omem=0 tot-mem=61490 events=r cmd=slaveof use |
slaveof是异步命令,执行完该命令后从节点保存主节点的host和port信息,但是并未真正开始复制;
2、创建socket连接,从节点内部定时每秒执行一次复制定时函数replicationCron,当发现存在可以连接主节点时就会根据主节点的信息创建socket连接,如果节点无法连接就会无限重试或者直到执行slaveof no one命令,此时redis会打印如下所示日志:
1 | * Connecting to MASTER 192.168.216.129:6379 |
此时主节点会给从节点的socket连接创建客户端状态并将其当作主节点上的一个客户端,使用client list命令是可以明确看到这个客户端的,如下所示:

3、从节点发送ping命令,等待主节点回复pong,用以检测socket是否可用以及主节点是否可接受处理命令,如果从节点接收响应超时或者接受到pong以外的响应,从节点就会断开复制链接,等待下次定时任务时再发起重连,日志如下:
1 | * Master replied to PING, replication can continue... |
4、masterauth验证,如果主节点设置了密码,那么此时需要验证密码才可以进行下一步操作,密码验证失败的话会断开连接,等待下一次重连;
5、数据同步,数据同步其实就是从节点的初始化的过程,数据同步包含全量同步以及部分同步,同步的过程后面具体分析,另外要注意一点的是在数据同步阶段主节点需要主动向从节点发送请求,因此此时主从节点互为客户端,数据同步对应的日志如下所示:
1 | * Trying a partial resynchronization (request 6c4167e7160b6bb316de536f24a93b1f260b2f10:1). |
6、持续性复制,经过前面五个步骤,正常情况下主从已经创建成功,之后主节点会源源不断的将写命令发送到从节点,从而保证主从一致性
增量同步
Redis增量复制是指Slave初始化后开始正常工作时主服务器发生的写操作同步到从服务器的过程。
增量复制的过程主要是主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令。
Redis主从同步策略
主从刚刚连接的时候,进行全量同步;全同步结束后,进行增量同步。当然,如果有需要,slave 在任何时候都可以发起全量同步。redis 策略是,无论如何,首先会尝试进行增量同步,如不成功,要求从机进行全量同步。
增量同步实现
1)从服务器向主服务器发送PSYNC命令,携带主服务器的runid和复制偏移量;
2)主服务器验证runid和自身runid是否一致,如不一致,则进行全量复制;
3)主服务器验证复制偏移量是否在积压缓冲区内,如不在,则进行全量复制;
4)如都验证通过,则主服务器将保持在积压区内的偏移量后的所有数据发送给从服务器,主从服务器再次回到一致状态。
注意点
如果多个Slave断线了,需要重启的时候,因为只要Slave启动,就会发送sync请求和主机全量同步,当多个同时出现的时候,可能会导致Master IO剧增宕机。
存在问题
1、复制风暴
产生原因:
当从服务器大量宕机之后,又同时启动。这个时候,从服务器同时去同步主服务器的redis,这个时候会产生大量的并发,导致主服务器宕机发生
解决方案:
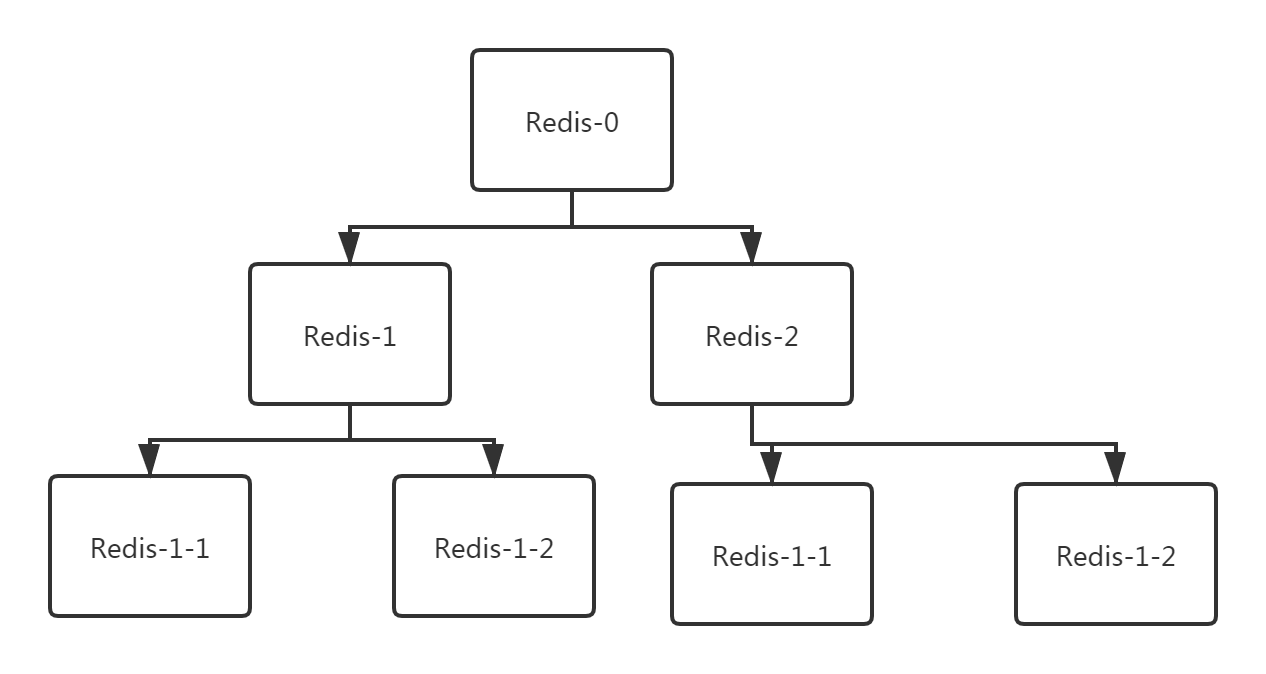
1、采用下方图示方案解决,一部分从节点挂到一些从节点上面。这个时候从库同步到主库的redis后,其他从库再从这个从库同步
2、采用多个主节点策略,就是多个master节点,这个就牵扯到了redis集群策略了
2、主从数据不同步
产生原因: 由于主库和从库的同步有一个过程,所以可能产生master库某些写入的数据,slave 短暂的读不到
如何解决:
1、如果这个数据不是很急的话,可以逻辑层面可以做一个延迟策略
2、如果你必须想要读取到这个数据,有这么几个办法:
3、 可以对slave的偏移量值进行监控,如果发现某台slave的偏移量有问题,则将数据读取操作切换到master,但本身这个监控开销比较高
3、读到过期数据(脏数据)
产生原因: redis在删除过期key的时候,是有两种策略,第一种是懒惰型策略,即只有当redis操作这个key的时候,发现这个key过期,就会把这个key删除。第二种是定期采样一些key进行删除
redis主从同步配置中,我们知道,redis里master和slave达成一种协议,slave是不能处理数据的(即不能删除数据)而我们的客户端没有及时读到到过期数据同步给master将key删除,就会导致slave读到过期的数据
如何解决:
这个问题已经在redis3.2版本中解决
4、数据延迟造成的脏数据
产生原因: master会异步的将数据复制到slave,如果这是slave发生阻塞,则会延迟master数据的写命令,造成数据不一致的情况
解决方案:
可以对slave的偏移量值进行监控,如果发现某台slave的偏移量有问题,则将数据读取操作切换到master
5、主从配置不一致
这个问题一般很少见,但如果有,就会发生很多诡异的问题
例如:
1. maxmemory配置不一致:这个会导致数据的丢失
原因:例如master配置4G,slave配置2G,这个时候主从复制可以成功,但,如果在进行某一次全量复制的时候,slave拿到master的RDB加载数据时发现自身的2G内存不够用,这时就会触发slave的maxmemory策略,将数据进行淘汰。更可怕的是,在高可用的集群环境下,如果我们将这台slave升级成master的时候,就会发现数据已经丢失了。
2. 数据结构优化参数不一致(例如hash-max-ziplist-entries):这个就会导致内存不一致
原因:例如在master上对这个参数进行了优化,而在slave没有配置,就会造成主从节点内存不一致的诡异问题。