相关链接
集群实现源码:https://github.com/redis/redis/blob/6.0/src/cluster.h
官网集群文档:https://redis.io/topics/cluster-tutorial
Redis集群smart jedis:https://kdocs.cn/l/soEOUpbcjY2q
Redis哈希槽概念:https://blog.mailjob.net/posts/2893278639.html
前言
本博客针对 redis5 以后的集群搭建进行讲解。
redis3 到 redis5 开始支持集群,用的是
ruby写的一个脚本,所以你需要先安装 ruby。然后根据官方提供了一个工具:redis-trib.rb(/redis-3.2.1/src/redis-trib.rb) 进行敲命令,一个个安装集群扩展。redis5以后的开发者们比较幸福了,redis直接支持了命令集群,在redis的
redis-cli客户端直接配置集群
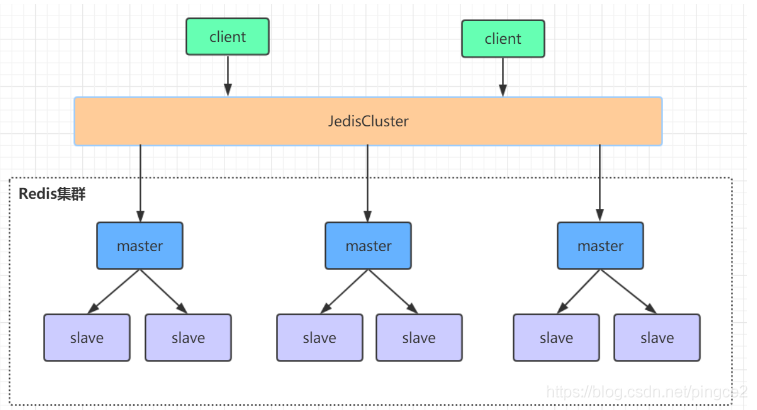
节点间的内部通信机制
1、基础通信原理
-
redis cluster节点间采取gossip协议进行通信
- 跟集中式不同,不是将集群元数据(节点信息,故障,等等)集中存储在某个节点上,而是互相之间不断通信,保持整个集群所有节点的数据是完整的
- 集中式:好处在于,元数据的更新和读取,时效性非常好,一旦元数据出现了变更,立即就更新到集中式的存储中,其他节点读取的时候立即就可以感知到; 不好在于,所有的元数据的跟新压力全部集中在一个地方,可能会导致元数据的存储有压力
- gossip:好处在于,元数据的更新比较分散,不是集中在一个地方,更新请求会陆陆续续,打到所有节点上去更新,有一定的延时,降低了压力; 缺点,元数据更新有延时,可能导致集群的一些操作会有一些滞后
-
10000端口
- 每个节点都有一个专门用于节点间通信的端口,就是自己提供服务的端口号+10000,比如7001,那么用于节点间通信的就是17001端口
- 每隔节点每隔一段时间都会往另外几个节点发送ping消息,同时其他几点接收到ping之后返回pong
-
交换的信息
- 故障信息,节点的增加和移除,hash slot信息,等等
2、gossip协议
gossip协议包含多种消息,包括ping,pong,meet,fail,等等
meet: 某个节点发送meet给新加入的节点,让新节点加入集群中,然后新节点就会开始与其他节点进行通信
redis-trib.rb add-node
其实内部就是发送了一个gossip meet消息,给新加入的节点,通知那个节点去加入我们的集群
ping: 每个节点都会频繁给其他节点发送ping,其中包含自己的状态还有自己维护的集群元数据,互相通过ping交换元数据
每个节点每秒都会频繁发送ping给其他的集群,ping,频繁的互相之间交换数据,互相进行元数据的更新
pong: 返回ping和meet,包含自己的状态和其他信息,也可以用于信息广播和更新
fail: 某个节点判断另一个节点fail之后,就发送fail给其他节点,通知其他节点,指定的节点宕机了
3、ping消息深入
ping很频繁,而且要携带一些元数据,所以可能会加重网络负担
每个节点每秒会执行10次ping,每次会选择5个最久没有通信的其他节点
当然如果发现某个节点通信延时达到了cluster_node_timeout / 2,那么立即发送ping,避免数据交换延时过长,落后的时间太长了
比如说,两个节点之间都10分钟没有交换数据了,那么整个集群处于严重的元数据不一致的情况,就会有问题
所以cluster_node_timeout可以调节,如果调节比较大,那么会降低发送的频率
每次ping,一个是带上自己节点的信息,还有就是带上1/10其他节点的信息,发送出去,进行数据交换
至少包含3个其他节点的信息,最多包含总节点-2个其他节点的信息
smart jedis
(1)什么是smart jedis
基于重定向的客户端,很消耗网络IO,因为大部分情况下,可能都会出现一次请求重定向,才能找到正确的节点
所以大部分的客户端,比如java redis客户端,就是jedis,都是smart的
本地维护一份hashslot -> node的映射表,缓存,大部分情况下,直接走本地缓存就可以找到hashslot -> node,不需要通过节点进行moved重定向
(2)JedisCluster的工作原理
在JedisCluster初始化的时候,就会随机选择一个node,初始化hashslot -> node映射表,同时为每个节点创建一个JedisPool连接池
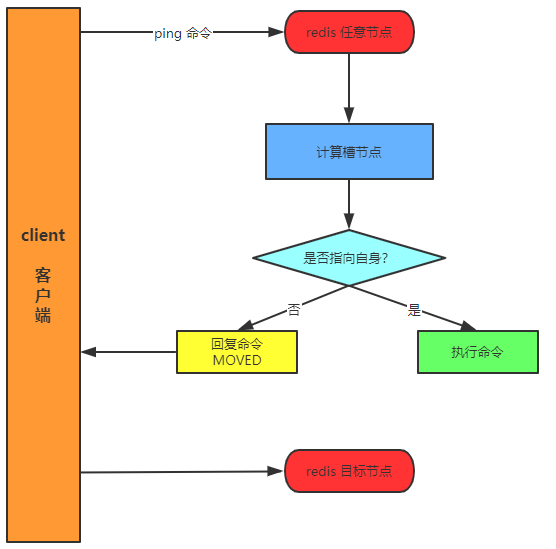
每次基于JedisCluster执行操作,首先JedisCluster都会在本地计算key的hashslot,然后在本地映射表找到对应的节点
如果那个node正好还是持有那个hashslot,那么就ok; 如果说进行了reshard这样的操作,可能hashslot已经不在那个node上了,就会返回moved
如果JedisCluter API发现对应的节点返回moved,那么利用该节点的元数据,更新本地的hashslot -> node映射表缓存
重复上面几个步骤,直到找到对应的节点,如果重试超过5次,那么就报错,JedisClusterMaxRedirectionException
jedis老版本,可能会出现在集群某个节点故障还没完成自动切换恢复时,频繁更新hash slot,频繁ping节点检查活跃,导致大量网络IO开销
jedis最新版本,对于这些过度的hash slot更新和ping,都进行了优化,避免了类似问题
(3)hashslot迁移和ask重定向
如果hash slot正在迁移,那么会返回ask重定向给jedis
jedis接收到ask重定向之后,会重新定位到目标节点去执行,但是因为ask发生在hash slot迁移过程中,所以JedisCluster API收到ask是不会更新hashslot本地缓存
已经可以确定说,hashslot已经迁移完了,moved是会更新本地hashslot->node映射表缓存的
故障转移:
redis集群实现了高可用,当集群内少量节点出现故障时,通过故障转移可以保证集群正常对外提供服务。
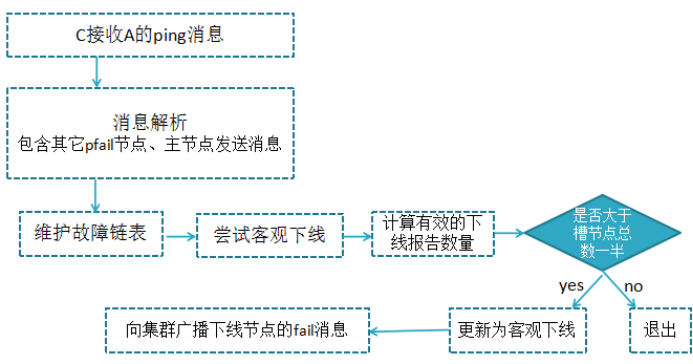
当集群里某个节点出现了问题,redis集群内的节点通过ping pong消息发现节点是否健康,是否有故障,其实主要环节也包括了 主观下线和客观下线;
主观下线:指某个节点认为另一个节点不可用,即下线状态,当然这个状态不是最终的故障判定,只能代表这个节点自身的意见,也有可能存在误判;
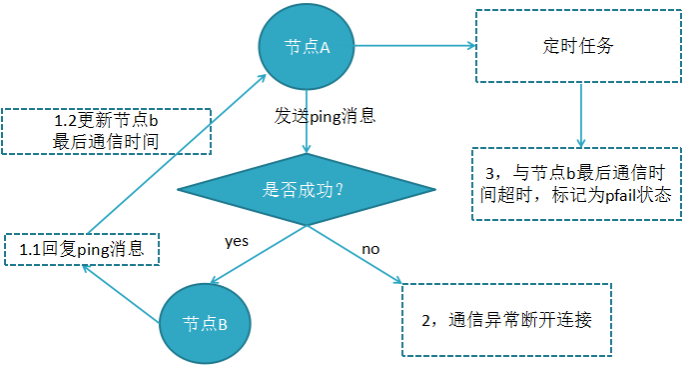
下线流程:
- 节点a发送ping消息给节点b ,如果通信正常将接收到pong消息,节点a更新最近一次与节点b的通信时间;
- 如果节点a与节点b通信出现问题则断开连接,下次会进行重连,如果一直通信失败,则它们的最后通信时间将无法更新;
- 节点a内的定时任务检测到与节点b最后通信时间超过cluster_note-timeout时,更新本地对节点b的状态为主观下线(pfail)
客观下线:
指真正的下线,集群内多个节点都认为该节点不可用,达成共识,将它下线,如果下线的节点为主节点,还要对它进行故障转移
假如节点a标记节点b为主观下线,一段时间后节点a通过消息把节点b的状态发到其它节点,当节点c接受到消息并解析出消息体时,会发现节点b的pfail状态时,会触发客观下线流程;
当下线为主节点时,此时redis集群为统计持有槽的主节点投票数是否达到一半,当下线报告统计数大于一半时,被标记为客观下线状态。
故障恢复:
故障主节点下线后,如果下线节点的是主节点,则需要在它的从节点中选一个替换它,保证集群的高可用;转移过程如下:
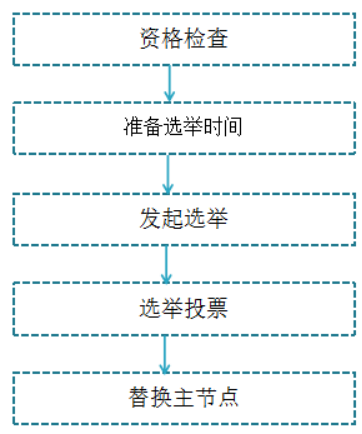
- 资格检查:检查该从节点是否有资格替换故障主节点,如果此从节点与主节点断开过通信,那么当前从节点不具体故障转移;
- 准备选举时间:当从节点符合故障转移资格后,更新触发故障选举时间,只有到达该时间后才能执行后续流程;
- 发起选举:当到达故障选举时间时,进行选举;
- 选举投票:只有持有槽的主节点才有票,会处理故障选举消息,投票过程其实是一个领导者选举(选举从节点为领导者)的过程,每个主节点只能投一张票给从节点,
当从节点收集到足够的选票(大于N/2+1)后,触发替换主节点操作,撤销原故障主节点的槽,委派给自己,并广播自己的委派消息,通知集群内所有节点