六种日志简介
慢查询日志 slow query log: 记录所有超过long_query_time时间的SQL语句,
二进制日志 binlog: 记录任何引起数据变化的操作,用于备份和还原。默认存放在数据目录中,在刷新和服务重启时会滚动二进制日志。
错误日志 errorlog: MySQL服务启动和关闭过程中的信息以及其它错误和警告信息。默认在数据目录下。
中继日志 relay log: 从主服务器的二进制文件中复制的事件,并保存为二进制文件,格式和二进制日志一样。
普通查询日志 general log: 用于记录select查询语句的日志。general_log、general_log_file 默认关闭,建议关闭。
事务日志: 保证事务一致性。重做日志(redo log)redo log在数据准备修改前写入缓存中的redo log中,然后才对缓存中的数据执行修改操作,而且保证在发出事务提交指令时,先向缓存中的redo log写入日志,写入完成后才执行提交动作。 回滚日志(undo log)提供回滚和多个行版本控制(MVCC)
日志小结:
- 重做日志(redo log)和回滚日志(undo log)与事务操作息息相关,二进制日志(binlog)也与事务操作有一定的关系
- undo log和redo log记录物理日志不一样,它是逻辑日志。可以认为当delete一条记录时,undo log中会记录一条对应的insert记录,反之亦然,当update一条记录时,它记录一条对应相反的update记录。
- 另外,undo log也会产生redo log,因为undo log也要实现持久性保护。
日志详解
慢查询日志
慢查询日志相关参数:
1 | # 是否开启慢查询,1开启,0关闭 |
参数配置
1 | # 查看日志类型 |
查看慢日志文件
如果慢日志存储为File文件,可以使用 cat -n 查看错误日志。如果慢日志存储为Table表,则使用 select 查看表记录。


1 | update `mp_tt_creative` set `image_md5` = 't1', `updated_at` = '1611023918' where (`image_ids` = 't2') and `image_md5` is null; |
通过对以上错误日志的查看,我们发现此处由于程序员对数据库采用循环操作,导致产生了
死锁现象。SQL执行时间是(Query_time): 1.456396 (默认超时是1s)。锁定时间是(Lock_time): 0.000028 。发送的行数(Rows_sent): 0 。检查的行数 (Rows_examined): 3925992
小妙招
推荐使用 mysqldumpslow 工具去查看慢日志文件
1 | # 得到返回记录集最多的10个SQL。 |
使用 pt-query-digest 工具进行分析
mysqldumpslow 是 mysql 安装后就自带的工具,用于分析慢查询日志,但是pt-query-digest却不是mysql自带的,如果想使用 pt-query-digest 进行慢查询日志的分析,则需要自己安装 pt-query-digest。pt-query-digest工具相较于mysqldumpslow功能多一点。
小结:
- 日志记录到系统的专用日志表中,要比记录到文件耗费更多的系统资源,因此对于需要启用慢查询日志,又需要能够获得更高的系统性能,那么建议优先记录到文件。
二进制日志
配置参数
1 | # # mysql5.7必须加,否则mysql服务启动报错 |
参数查看
1 | # 查看二进制日志设置 |
二进制日志的三种模式
二进制日志三种格式:STATEMENT,ROW,MIXED,由参数 binlog_format 控制
STATEMENT模式(SBR)
每一条会修改数据的sql语句会记录到binlog中。
优点:并不需要记录每一条sql语句和每一行的数据变化,减少了binlog日志量,节约IO,提高性能。
缺点:在某些情况(如非确定函数)下会导致master-slave中的数据不一致 < 如sleep()函数, last_insert_id(),以及user-defined functions(udf)等会出现问题 >
ROW模式(RBR)
不记录每条sql语句的上下文信息,仅需记录哪条数据被修改了,修改成什么样了。而且不会出现某些特定情况下的存储过程、或function、或trigger的调用和触发无法被正确复制的问题。
缺点:会产生大量的日志,尤其是alter table的时候会让日志暴涨。
MIXED模式(MBR)
以上两种模式的混合使用,一般的复制使用STATEMENT模式保存binlog,对于STATEMENT模式无法复制的操作使用ROW模式保存binlog,MySQL会根据执行的SQL语句选择日志保存方式
二进制日志恢复数据库
如果开启了二进制日志,出现了数据丢失,可以通过二进制日志恢复数据库,语法如下
1 | mysqlbinlog [option] filename | mysql -u user -p passwd |
option 的参数主要有两个 --start-datetime 、 --stop-datetime 和 start-position 、 --stop-position
前者指定恢复的时间点,后者指定恢复的位置。原理就是把记录的语句重新执行了一次,如果恢复了两次。会产生重复数据。
1 | mysqlbinlog --start-position="291" --stop-position="439" /data/3306/tmp/binlog/mysql-bin.000001 | mysql -uroot -p123456 |
注意:要找到插入更新的语句所在的时间点或位置。如果恢复的语句包含只有 delete,会报错1032错误。
错误日志
相关配置
在 MySQL 数据库中,默认开启错误日志功能。一般情况下,错误日志存储在 MySQL 数据库的数据文件夹下,通常名称为 hostname.err。其中,hostname 表示 MySQL 服务器的主机名。
在 MySQL 配置文件中,错误日志所记录的信息可以通过 log-error 和 log-warnings 来定义,其中,log-err 定义是否启用错误日志功能和错误日志的存储位置,log-warnings 定义是否将警告信息也记录到错误日志中。
将 log_error 选项加入到 MySQL 配置文件的 [mysqld]组中,形式如下:
1 | [mysqld] |
其中,dir 参数指定错误日志的存储路径;filename 参数指定错误日志的文件名;省略参数时文件名默认为主机名,存放在 Data 目录中。
注意:错误日志中记录的并非全是错误信息,例如 MySQL 如何启动 InnoDB 的表空间文件、如何初始化自己的存储引擎等,这些也记录在错误日志文件中。
1 | #查看当前的错误日志配置,缺省情况下位于数据目录 |
通过tail查看错误日志,得到信息如下:
可以看到,获取的包已超过最大限制值,连接被中断
1 | [root@ruidao104 var]# tail -3 ruidao104.err |
中继日志
什么是中继日志???
从服务器 I/O 线程将主服务器的二进制日志读取过来记录到从服务器本地文件,然后从服务器 SQL 线程会读取 relay-log 日志的内容并应用到从服务器,从而使从服务器和主服务器的数据保持一致
相关配置:
1 | # 查看中继日志配置信息 |
max_relay_log_size: relay log 允许的最大值,如果该值为0,则默认值为 max_binlog_size (1G)
relay_log: 定义 relay_log 的位置和名称,如果值为空,则默认位置在数据文件的目录;
relay_log_index: 定义 relay_log 索引的位置和名称,记录有几个 relay_log 文件,默认为2个
relay_log_info_file: 定义 relay-log.info 的位置和名称。relay-log.info 记录 master 主库的 binary_log 的恢复位置和 从库 relay_log 的位置;
relay_log_recovery: 当slave从库宕机后,假如relay-log损坏了,导致一部分中继日志没有处理,则自动放弃所有未执行的relay-log,并且重新从master上获取日志,这样就保证了relay-log的完整性。默认情况下该功能是关闭的,将relay_log_recovery的值设置为 1时,可在slave从库上开启该功能,建议开启。
relay_log_space_limit: 防止中继日志写满磁盘,这里设置中继日志最大限额。但此设置存在主库崩溃,从库中继日志不全的情况,不到万不得已不推荐使用
relay_log_purge: 是否自动清空中继日志,默认值为1(启用);
**sync_relay_log: **当设置为1时,slave的I/O线程每次接收到master发送过来的binlog日志都要写入系统缓冲区,然后刷入relay log中继日志里,这样是最安全的,因为在崩溃的时候,你最多会丢失一个事务,但会造成磁盘的大量I/O。当设置为0时,并不是马上就刷入中继日志里,而是由操作系统决定何时来写入,虽然安全性降低了,但减少了大量的磁盘I/O操作。这个值默认是0,可动态修改。
sync_relay_log_info: 这个参数和 sync_relay_log 参数一样。
mysql主从原理图
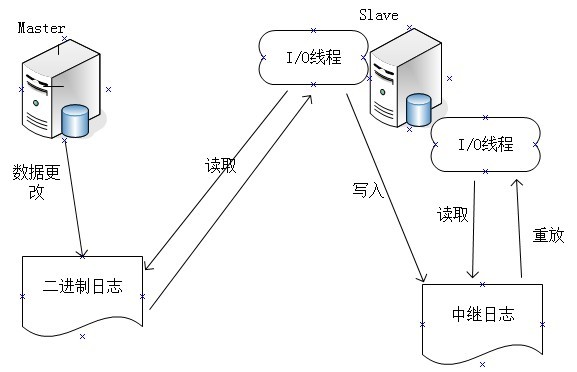
主从简单说明: 从上图中,可以看出。mysql主服务器执行了一个 update 操作后,从库生成了两个线程,一个IO线程,一个SQL线程 。主库将 binlog发送给 从库 I/O 线程,从库 I/O 线程将 binlog 写入 relay log(中继日志)。从库的 SQL 线程,会读取 relay log 文件中的日志,并解析成具体操作执行,实现主从最终数据一致;
小结:
- 中继日志生效于mysql主从复制过程中的从服务器上。
- 它的任务就是,解析 binlog 日志,判断偏移量,根据偏移量对数据库做出DDL的操作,最终实现mysql的主从一致。
普通查询日志
开启 general log 将所有到达MySQL Server的SQL语句记录下来。
一般不会开启开功能,因为log的量会非常庞大。但个别情况下可能会临时的开一会儿general log以供排障使用。
相关参数一共有3:general_log、log_output、general_log_file
1 | show variables like 'general_log'; -- 查看日志是否开启 |
事务日志
初步认识事务日志
InnoDB 事务日志一共分为两个,重做日志,回滚日志。redo log是重做日志,提供前滚操作。undo log是回滚日志,提供回滚操作。
undo log不是redo log的逆向过程,其实它们都算是用来恢复的日志:
- redo log通常是物理日志,记录的是数据页的物理修改,而不是某一行或某几行修改成怎样怎样,它用来恢复提交后的物理数据页(恢复数据页,且只能恢复到最后一次提交的位置)。
- undo log 用来回滚行记录到某个版本。undo log一般是
逻辑日志,根据每行记录进行记录(为了更好的理解 undo log 请学习一下mysql 的 MVCC)。
案例分析两个日志的区别
通过 update 伪代码进行演示
1 | # 初始内容 |
undo 回滚日志记录信息如下:
1 | UPDATE user SET name = '阿里巴巴' WHERE id = 1 |
redo log 重做日志File记录信息如下:
1 | UPDATE user SET name = '百度' WHERE id = 1 |
另外,undo log也会产生redo log,因为undo log也要实现持久性保护
REDO LOG详解
为了更好的理解 redo log 请先学习:Mysql checkpoint 和 Linux fsync。checkpoint:https://www.cnblogs.com/lintong/p/4381578.html
REDO LOG 和 BIN LOG的区别:
- redo log是属于innoDB层面,binlog属于MySQL Server层面的,这样在数据库用别的存储引擎时可以达到一致性的要求。
- redo log是物理日志,记录该数据页更新的内容;binlog是逻辑日志,记录的是这个更新语句的原始逻辑
- redo log是循环写,日志空间大小固定;binlog是追加写,是指一份写到一定大小的时候会更换下一个文件,不会覆盖。
- binlog可以作为恢复数据使用,主从复制搭建,redo log作为异常宕机或者介质故障后的数据恢复使用。
REDO LOG 基本概念:
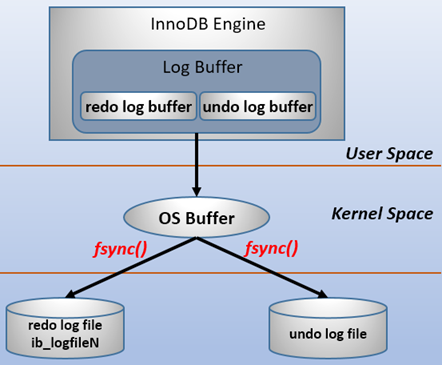
redo log 包括两部分:一是内存中的日志缓冲(redo log buffer),该部分日志是易失性的;二是磁盘上的重做日志文件(redo log file),该部分日志是持久的
为了确保每次日志都能写入到事务日志文件中,在每次将log buffer中的日志写入日志文件的过程中都会调用一次操作系统的fsync操作(即fsync()系统调用)。
也就是说,从redo log buffer写日志到磁盘的redo log file中,过程如下(关系写入规则,可阅读 < mysql的 IO 流程 >):
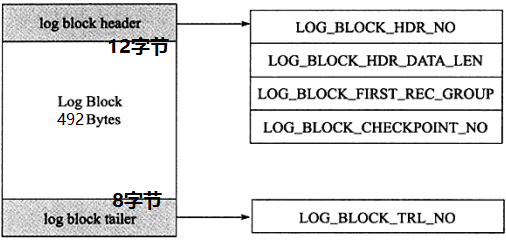
REDO LOG的日志块(log block)
innodb存储引擎中,redo log以块为单位进行存储的,每个块占 512字节(byte),这称为 redo log block。所以不管是 log buffer 中还是 os buffer 中以及 redo log file on disk 中,都是这样以512字节的块存储的。
每个redo log block由3部分组成**:日志块头、日志块尾和日志主体**。其中日志块头占用12字节,日志块尾占用8字节,所以每个redo log block的日志主体部分只有512-12-8=492字节。
InnoDB事务恢复行为
在启动innodb的时候,不管上次是正常关闭还是异常关闭,总是会进行恢复操作。
因为redo log记录的是数据页的物理变化,因此恢复的时候速度比逻辑日志(如二进制日志)要快很多。而且,innodb自身也做了一定程度的优化,让恢复速度变得更快。
重启innodb时,checkpoint表示已经完整刷到磁盘上data page上的LSN,因此恢复时仅需要恢复从checkpoint开始的日志部分。例如,当数据库在上一次checkpoint的LSN为10000时宕机,且事务是已经提交过的状态。启动数据库时会检查磁盘中数据页的LSN,如果数据页的LSN小于日志中的LSN,则会从检查点开始恢复。
还有一种情况,在宕机前正处于checkpoint的刷盘过程,且数据页的刷盘进度超过了日志页的刷盘进度。这时候一宕机,数据页中记录的LSN就会大于日志页中的LSN,在重启的恢复过程中会检查到这一情况,这时超出日志进度的部分将不会重做,因为这本身就表示已经做过的事情,无需再重做。
另外,事务日志具有幂等性,所以多次操作得到同一结果的行为在日志中只记录一次。而二进制日志不具有幂等性,多次操作会全部记录下来,在恢复的时候会多次执行二进制日志中的记录,速度就慢得多。例如,某记录中id初始值为2,通过update将值设置为了3,后来又设置成了2,在事务日志中记录的将是无变化的页,根本无需恢复;而二进制会记录下两次update操作,恢复时也将执行这两次update操作,速度比事务日志恢复更慢。
UNDO LOG详解
为了更好的理解 undo log 请先学习:隔离机制,事务,mvcc。
基本概念:
undo log有两个作用:提供回滚和多个行版本控制(MVCC)。
在数据修改的时候,不仅记录了redo,还记录了相对应的undo,如果因为某些原因导致事务失败或回滚了,可以借助该undo进行回滚。
undo log和redo log记录物理日志不一样,它是逻辑日志。可以认为当delete一条记录时,undo log中会记录一条对应的insert记录,反之亦然,当update一条记录时,它记录一条对应相反的update记录。
当执行rollback时,就可以从 undo log 中的逻辑记录读取到相应的内容并进行回滚。
有时候应用到行版本控制的时候,也是通过 undo log 来实现的:当读取的某一行被其他事务锁定时,它可以从undo log 中分析出该行记录以前的数据是什么,从而提供该行版本信息,让用户实现非锁定一致性读取。
另外,undo log 也会产生 redo log,因为 undo log 也要实现持久性保护。
UNDO LOG存储方式
innodb存储引擎对undo的管理采用段的方式。rollback segment称为回滚段,每个回滚段中有1024个undo log segment。
在以前老版本,只支持1个rollback segment,这样就只能记录1024个undo log segment。后来MySQL5.5可以支持128个rollback segment,即支持128*1024个undo操作,还可以通过变量 innodb_undo_logs (5.6版本以前该变量是 innodb_rollback_segments )自定义多少个rollback segment,默认值为128。
undo log默认存放在共享表空间中。
1 | [root@xuexi data]# ll /mydata/data/ib* |
如果开启了 innodb_file_per_table ,将放在每个表的.ibd文件中。
在MySQL5.6中,undo的存放位置还可以通过变量 innodb_undo_directory 来自定义存放目录,默认值为"."表示datadir。
默认rollback segment全部写在一个文件中,但可以通过设置变量 innodb_undo_tablespaces 平均分配到多少个文件中。该变量默认值为0,即全部写入一个表空间文件。该变量为静态变量,只能在数据库示例停止状态下修改,如写入配置文件或启动时带上对应参数。但是innodb存储引擎在启动过程中提示,不建议修改为非0的值,如下:
1 | 2017-03-31 13:16:00 7f665bfab720 InnoDB: Expected to open 3 undo tablespaces but was able |
DELETE/UPDATE操作的内部机制
当事务提交的时候,innodb 不会立即删除undo log,因为后续还可能会用到 undo log,如隔离级别为RR时,事务读取的都是开启事务时的最新提交行版本,只要该事务不结束,该行版本就不能删除,即 undo log 不能删除。
但是在事务提交的时候,会将该事务对应的 undo log 放入到删除列表中,未来通过purge来删除。并且提交事务时,还会判断 undo log 分配的页是否可以重用,如果可以重用,则会分配给后面来的事务,避免为每个独立的事务分配独立的undo log页而浪费存储空间和性能。
通过undo log记录delete和update操作的结果发现:(insert操作无需分析,就是插入行而已)
- delete操作实际上不会直接删除,而是将delete对象打上delete flag,标记为删除,最终的删除操作是purge线程完成的。
- update分为两种情况:update的列是否是主键列。
- 如果不是主键列,在undo log中直接反向记录是如何update的。即update是直接进行的。
- 如果是主键列,update分两部执行:先删除该行,再插入一行目标行。
总结
BinLog和事务日志的先后顺序及group commit
为了提高性能,通常会将有关联性的多个数据修改操作放在一个事务中,这样可以避免对每个修改操作都执行完整的持久化操作。这种方式,可以看作是人为的组提交(group commit)。
除了将多个操作组合在一个事务中,记录binlog的操作也可以按组的思想进行优化:将多个事务涉及到的binlog一次性flush,而不是每次flush一个binlog。
事务在提交的时候不仅会记录事务日志,还会记录二进制日志,但是它们谁先记录呢?二进制日志是MySQL的上层日志,先于存储引擎的事务日志被写入。
在
MySQL5.6以前,当事务提交(即发出commit指令)后,MySQL接收到该信号进入commit prepare阶段;进入prepare阶段后,立即写内存中的二进制日志,写完内存中的二进制日志后就相当于确定了commit操作;然后开始写内存中的事务日志;最后将二进制日志和事务日志刷盘,它们如何刷盘,分别由变量sync_binlog 和 innodb_flush_log_at_trx_commit 控制。
但因为要保证二进制日志和事务日志的一致性,在提交后的prepare阶段会启用一个prepare_commit_mutex锁来保证它们的顺序性和一致性。但这样会导致开启二进制日志后group commmit失效,特别是在主从复制结构中,几乎都会开启二进制日志。
在MySQL5.6中进行了改进。提交事务时,在存储引擎层的上一层结构中会将事务按序放入一个队列,队列中的第一个事务称为leader,其他事务称为follower,leader控制着follower的行为。虽然顺序还是一样先刷二进制,再刷事务日志,但是机制完全改变了:删除了原来的prepare_commit_mutex行为,也能保证即使开启了二进制日志,group commit也是有效的。
MySQL5.6中分为3个步骤**:flush阶段、sync阶段、commit阶段。**
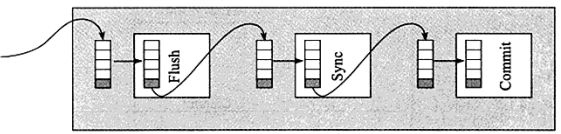
- flush阶段: 向内存中写入每个事务的二进制日志。
- sync阶段: 将内存中的二进制日志刷盘。若队列中有多个事务,那么仅一次fsync操作就完成了二进制日志的刷盘操作。这在MySQL5.6中称为BLGC(binary log group commit)。
- commit阶段: leader根据顺序调用存储引擎层事务的提交,由于innodb本就支持group commit,所以解决了因为锁 prepare_commit_mutex 而导致的group commit失效问题。
在flush阶段写入二进制日志到内存中,但是不是写完就进入sync阶段的,而是要等待一定的时间,多积累几个事务的binlog一起进入sync阶段,等待时间由变量 binlog_max_flush_queue_time 决定,默认值为0表示不等待直接进入sync,设置该变量为一个大于0的值的好处是group中的事务多了,性能会好一些,但是这样会导致事务的响应时间变慢,所以建议不要修改该变量的值,除非事务量非常多并且不断的在写入和更新。
进入到sync阶段,会将binlog从内存中刷入到磁盘,刷入的数量和单独的二进制日志刷盘一样,由变量 sync_binlog 控制。
当有一组事务在进行commit阶段时,其他新事务可以进行flush阶段,它们本就不会相互阻塞,所以group commit会不断生效。当然,group commit的性能和队列中的事务数量有关,如果每次队列中只有1个事务,那么group commit和单独的commit没什么区别,当队列中事务越来越多时,即提交事务越多越快时,group commit的效果越明显。