相关链接
Redis 常用命令,思维导图 :https://www.kdocs.cn/view/l/ss49IFenIOSm
List
是一个字符串链表
Left、right都可插入元素
如果,key不存在,创建链表
如果,key存在,链表添加内容
如果,链表值全部移除,key也就消失了
效率分析
链表的头尾元素操作,效率都非常高
链表中间元素操作,效率比较低
List 底层实现
链表是一种常用的数据结构,C 语言内部是没有内置这种数据结构的实现,所以Redis自己构建了链表的实现
链表的定义
1 | typedef struct listNode{ |
通过多个 listNode 结构就可以组成链表,这是一个双向链表,Redis还提供了操作链表的数据结构
1 | typedef struct list{ |
在版本3.2之前,Redis 列表list使用两种数据结构作为底层实现:
- 压缩列表ziplist
- 双向链表linkedlist
因为双向链表占用的内存比压缩列表要多, 所以当创建新的列表键时, 列表会优先考虑使用压缩列表, 并且在有需要的时候, 才从压缩列表实现转换到双向链表实现
zipList
**压缩列表 ziplist 的原理:压缩列表并不是对数据利用某种算法进行压缩,**而是将数据按照一定规则编码在一块连续的内存区域,目的是节省内存
*当元素个数较少时,Redis 用 ziplist 来存储数据,当元素个数超过某个值时,链表键中会把 ziplist 转化为 linkedlist,字典键中会把 ziplist 转化为 hashtable。
由于内存是连续分配的,所以遍历速度很快。*在3.2之后,*ziplist被quicklist替代*。但是仍然是zset底层实现之一
quickList就是一个标准的双向链表的配置,有head 有tail;
每一个节点是一个quicklistNode,包含prev和next指针。
每一个quicklistNode 包含 一个ziplist,*zp 压缩链表里存储键值。
所以quicklist是对ziplist进行一次封装,使用小块的ziplist来既保证了少使用内存,也保证了性能。
- 下图展示了压缩列表的各个组成部分
- 下表则记录了各个组成部分的类型、长度以及用途
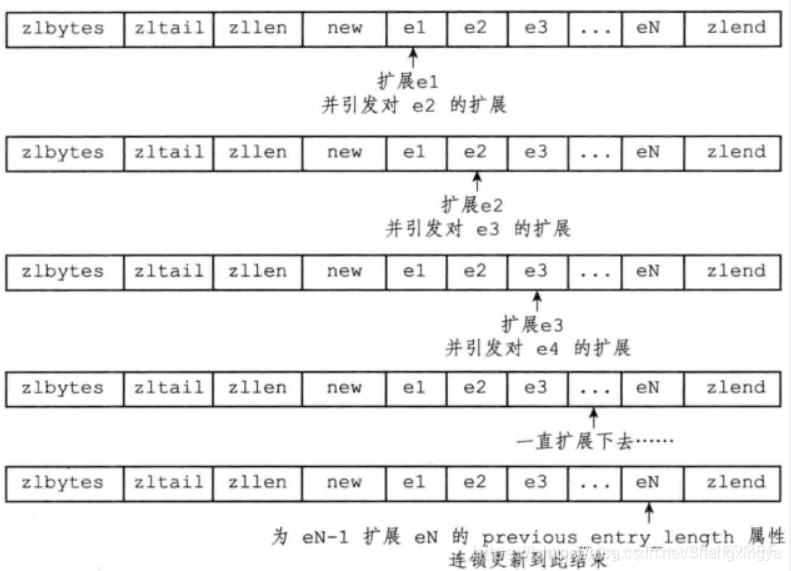
连锁更新
- 使用压缩链表使, 放置的数据是有限制的, 自如字符个数要在64个以内, 但是如果出现这种情况, 连续节点放置的数据都是63个, 如果突然第一个节点的字符超过了64个需要扩展, 因为压缩列表使用的内存是连续的, 所以后面的节点也应该扩展
尽管连锁更新的复杂度较高,但它真正造成性能问题的几率是很低的:
- 首先,压缩列表里要恰好有多个连续的、长度介于250字节至253字节之间的节点,连锁 更新才有可能被引发,在实际中,这种情况并不多见
- 其次,即使出现连锁更新,但只要被更新的节点数量不多,就不会对性能造成任何影 响:比如说,对三五个节点进行连锁更新是绝对不会影响性能的
因为以上原因,ziplistPush等命令的平均复杂度仅为O(N),在实际中,我们可以放心 地使用这些函数,而不必担心连锁更新会影响压缩列表的性能
因为连锁更新在最坏情况下需要对压缩列表执行N次空间重分配操作,而每次空间重分配的最坏复杂度为O(N),所以连锁更新的最坏复杂度为O(N^{2})


linkedlist
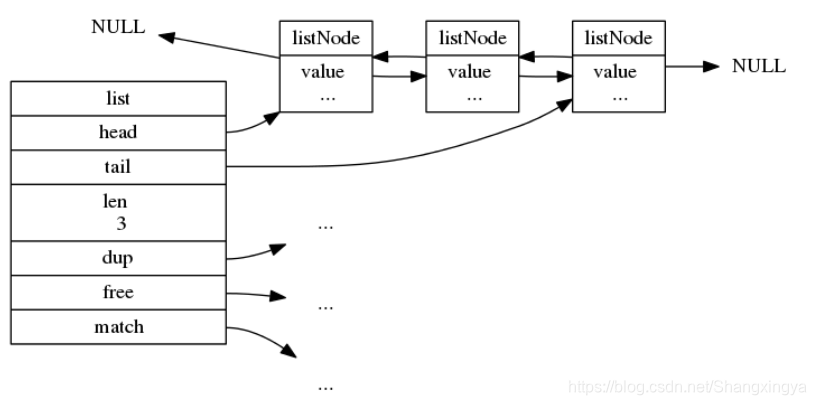
- 多个listNode可以通过prev和next指针组成双端链表,如下图所示:
- 从上面的结构可以看出,Redis的链表是一个带头尾节点的双向无环链表,并且通过len字段记录了链表节点的长度
- list结构为链表提供了表头指针head、表尾指针tail,以及链表长度计数器len
- dup、 free和match成员则是用于实现多态链表所需的类型特定函数:
- dup函数用于复制链表节点所保存的值
- free函数用于释放链表节点所保存的值
- match函数则用于对比链表节点所保存的值和另一个输入值是否相等
总结Redis的链表实现的特性
- 双向:链表节点带有prev和next指针,获取某个节点的前置节点和后置节点的复杂度都 是O(1)
- 无环:表头节点的prev指针和表尾节点的next指针都指向NULL,对链表的访问以 NULL为终点
- 带表头指针和表尾指针:通过list结构的head指针和tail指针,程序获取链表的表头节点 和表尾节点的复杂度为O(1)
- 带链表长度计数器:程序使用list结构的len属性来对list持有的链表节点进行计数,程序 获取链表中节点数量的复杂度为O(1)
- 多态:链表节点使用void*指针来保存节点值,并且可以通过list结构的dup、free、 match三个属性为节点值设置类型特定函数,所以链表可以用于保存各种不同类型的值

总结
双向链表,每个数据都有头和尾。但是压缩列表,只有一个头和尾,然后吧所有的数据都放在了中间,所以使用的内存最小
压缩列表转化成双向链表条件
创建新列表时 redis 默认使用 redis_encoding_ziplist 编码, 当以下任意一个条件被满足时, 列表会被转换成 redis_encoding_linkedlist 编码:
- 试图往列表新添加一个字符串值,且这个字符串的长度超过 server.list_max_ziplist_value (默认值为 64 )。
- ziplist 包含的节点超过 server.list_max_ziplist_entries (默认值为 512 )。
注意:这两个条件是可以修改的,在 redis.conf 中:
1 | // 保存的所有元素成员的长度都小于64字节 |
Redis List 应用场景
1、消息队列
如下图所示,Redis的lpush + brpop命令组合即可实现阻塞队列,生产者使用 lpush 从列表左侧插入元素,多个消费者客户端使用 brpop 命令阻塞式的争抢列表尾部的元素,多个客户端保证了消费的负载均衡和高可用;
2、最新列表
list类型的lpush命令和lrange命令能实现最新列表的功能,每次通过lpush命令往列表里插入新的元素,然后通过lrange命令读取最新的元素列表,如朋友圈的点赞列表、评论列表。
但是,并不是所有的最新列表都能用list类型实现,因为对于频繁更新的列表,list类型的分页可能导致列表元素重复或漏掉,
举个例子,当前列表里由表头到表尾依次有(E,D,C,B,A)五个元素,每页获取3个元素,用户第一次获取到(E,D,C)三个元素,然后表头新增了一个元素F,列表变成了(F,E,D,C,B,A),此时用户取第二页拿到(C,B,A),元素C重复了。只有不需要分页(比如每次都只取列表的前5个元素)或者更新频率低(比如每天凌晨更新一次)的列表才适合用list类型实现。
对于需要分页并且会频繁更新的列表,需用使用有序集合sorted set类型实现。
另外,需要通过时间范围查找的最新列表,list类型也实现不了,也需要通过有序集合sorted set类型实现,如以成交时间范围作为条件来查询的订单列表
3、排行榜
list类型的lrange命令可以分页查看队列中的数据。可将每隔一段时间计算一次的排行榜存储在list类型中,如京东每日的手机销量排行、学校每次月考学生的成绩排名、斗鱼年终盛典主播排名等,每日计算一次,存储在list类型中,接口访问时,通过page和size分页获取排行榜。
但是,并不是所有的排行榜都能用list类型实现,只有定时计算的排行榜才适合使用list类型存储,与定时计算的排行榜相对应的是实时计算的排行榜,list类型不能支持实时计算的排行榜
操作命令

1 | 1、redis中list列表的数据插入命令:lpush,rpush,linsert |