背景
该文章是基于**重做日志(redo log)**的内容补充。
mysql服务器宕机后,对于数据库的恢复,这个过程中也离不开**重做日志(redo log)**和 Checkpoint 的支持。
参考文献
Checkpoint思维导图:https://kdocs.cn/l/sc2IGPK1MWgD
前言
思考一下这个场景:如果重做日志可以无限地增大,同时缓冲池也足够大,那么是不需要将缓冲池中页的新版本刷新回磁盘。因为当发生宕机时,完全可以通过重做日志来恢复整个数据库系统中的数据到宕机发生的时刻。
但是这需要两个前提条件:
1、缓冲池可以缓存数据库中所有的数据;
2、重做日志可以无限增大
因此Checkpoint(检查点)技术就诞生了,目的是解决以下几个问题:
1、缩短数据库的恢复时间;
2、缓冲池不够用时,将脏页刷新到磁盘;
3、重做日志不可用时,刷新脏页。
- 当数据库发生宕机时,数据库不需要重做所有的日志,因为Checkpoint之前的页都已经刷新回磁盘。数据库只需对Checkpoint后的重做日志进行恢复,这样就大大缩短了恢复的时间。
- 当缓冲池不够用时,根据
LRU算法会溢出最近最少使用的页,若此页为脏页,那么需要强制执行Checkpoint,将脏页也就是页的新版本刷回磁盘。- 当重做日志出现不可用时,因为当前事务数据库系统对重做日志的设计都是循环使用的,并不是让其无限增大的,重做日志可以被重用的部分是指这些重做日志已经不再需要,当数据库发生宕机时,数据库恢复操作不需要这部分的重做日志,因此这部分就可以被覆盖重用。如果重做日志还需要使用,那么必须强制Checkpoint,将缓冲池中的页至少刷新到当前重做日志的位置。
innoDB - LNS
对于InnoDB存储引擎而言,是通过LSN(Log Sequence Number)来标记版本的。
LSN是8字节的数字,每个页有LSN,重做日志中也有LSN,Checkpoint也有LSN。
1 | # 可以通过命令(show engine innodb status)来观察 |
根据LSN,可以获取到几个有用的信息:
1.数据页的版本信息。
2.写入的日志总量,通过LSN开始号码和结束号码可以计算出写入的日志量。
3.可知道检查点的位置。
实际上还可以获得很多隐式的信息。
LSN不仅存在于redo log中,还存在于数据页中,在每个数据页的头部,有一个fil_page_lsn记录了当前页最终的LSN值是多少。通过数据页中的LSN值和redo log中的LSN值比较,如果页中的LSN值小于redo log中LSN值,则表示数据丢失了一部分,这时候可以通过redo log的记录来恢复到redo log中记录的LSN值时的状态。
其中:
- log sequence number就是当前的redo log(in buffer)中的lsn;
- log flushed up to是刷到redo log file on disk中的lsn;
- pages flushed up to是已经刷到磁盘数据页上的LSN;
- last checkpoint at是上一次检查点所在位置的LSN。
innodb执行修改语句演示LNS
1、首先修改内存中的数据页,并在数据页中记录LSN,暂且称之为data_in_buffer_lsn;
2、并且在修改数据页的同时(几乎是同时)向redo log in buffer中写入redo log,并记录下对应的LSN,暂且称之为redo_log_in_buffer_lsn;
3、写完buffer中的日志后,当触发了日志刷盘的几种规则时,会向redo log file on disk刷入redo重做日志,并在该文件中记下对应的LSN,暂且称之为redo_log_on_disk_lsn;
4、数据页不可能永远只停留在内存中,在某些情况下,会触发checkpoint来将内存中的脏页(数据脏页和日志脏页)刷到磁盘,所以会在本次checkpoint脏页刷盘结束时,在redo log中记录checkpoint的LSN位置,暂且称之为checkpoint_lsn。
5、要记录checkpoint所在位置很快,只需简单的设置一个标志即可,但是刷数据页并不一定很快,例如这一次checkpoint要刷入的数据页非常多。也就是说要刷入所有的数据页需要一定的时间来完成,中途刷入的每个数据页都会记下当前页所在的LSN,暂且称之为data_page_on_disk_lsn。
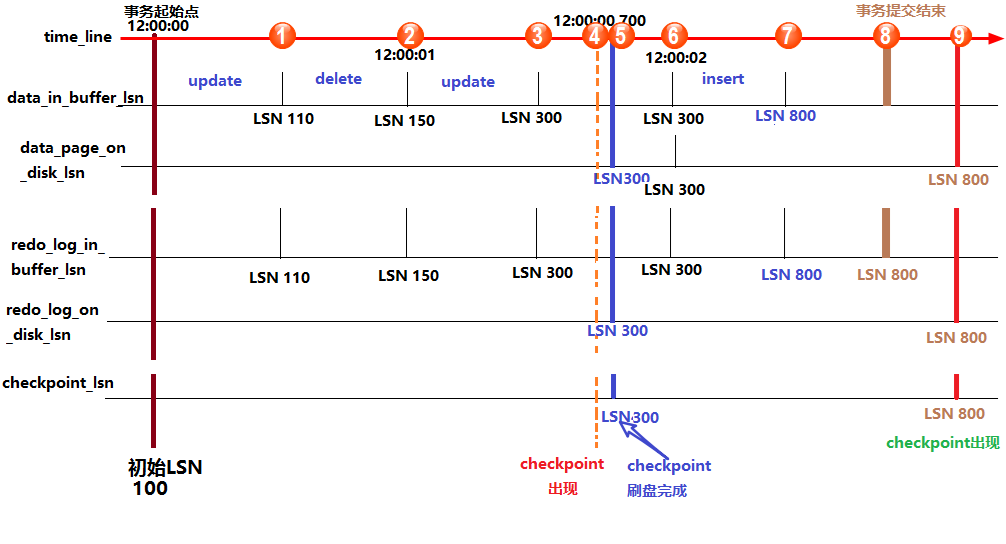
上图中,从上到下的横线分别代表:时间轴、buffer中数据页中记录的LSN(data_in_buffer_lsn)、磁盘中数据页中记录的LSN(data_page_on_disk_lsn)、buffer中重做日志记录的LSN(redo_log_in_buffer_lsn)、磁盘中重做日志文件中记录的LSN(redo_log_on_disk_lsn)以及检查点记录的LSN(checkpoint_lsn)。
假设在最初时(12:00:00)所有的日志页和数据页都完成了刷盘,也记录好了检查点的LSN,这时它们的LSN都是完全一致的。
假设此时开启了一个事务,并立刻执行了一个update操作,执行完成后,buffer中的数据页和redo log都记录好了更新后的LSN值,假设为110。
这时候如果执行 show engine innodb status 查看各LSN的值,即图中①处的位置状态,结果会是:
1 | log sequence number(110) > log flushed up to(100) = pages flushed up to = last checkpoint at |
之后又执行了一个delete语句,LSN增长到150。等到12:00:01时,触发redo log刷盘的规则(其中有一个规则是 innodb_flush_log_at_timeout 控制的默认日志刷盘频率为1秒),这时redo log file on disk中的LSN会更新到和redo log in buffer的LSN一样,所以都等于150,这时 show engine innodb status ,即图中②的位置,结果将会是:
1 | log sequence number(150) = log flushed up to > pages flushed up to(100) = last checkpoint at |
再之后,执行了一个update语句,缓存中的LSN将增长到300,即图中③的位置。
假设随后检查点出现,即图中④的位置,正如前面所说,检查点会触发数据页和日志页刷盘,但需要一定的时间来完成,所以在数据页刷盘还未完成时,检查点的LSN还是上一次检查点的LSN,但此时磁盘上数据页和日志页的LSN已经增长了,即:
1 | log sequence number > log flushed up to 和 pages flushed up to > last checkpoint at |
但是log flushed up to和pages flushed up to的大小无法确定,因为日志刷盘可能快于数据刷盘,也可能等于,还可能是慢于。但是checkpoint机制有保护数据刷盘速度是慢于日志刷盘的:当数据刷盘速度超过日志刷盘时,将会暂时停止数据刷盘,等待日志刷盘进度超过数据刷盘。
等到数据页和日志页刷盘完毕,即到了位置⑤的时候,所有的LSN都等于300。
随着时间的推移到了12:00:02,即图中位置⑥,又触发了日志刷盘的规则,但此时buffer中的日志LSN和磁盘中的日志LSN是一致的,所以不执行日志刷盘,即此时 show engine innodb status 时各种lsn都相等。
随后执行了一个insert语句,假设buffer中的LSN增长到了800,即图中位置⑦。此时各种LSN的大小和位置①时一样。
随后执行了提交动作,即位置⑧。默认情况下,提交动作会触发日志刷盘,但不会触发数据刷盘,所以 show engine innodb status 的结果是:
1 | log sequence number = log flushed up to > pages flushed up to = last checkpoint at |
最后随着时间的推移,检查点再次出现,即图中位置⑨。但是这次检查点不会触发日志刷盘,因为日志的LSN在检查点出现之前已经同步了。假设这次数据刷盘速度极快,快到一瞬间内完成而无法捕捉到状态的变化,这时 show engine innodb status 的结果将是各种LSN相等。
innodb的恢复行为
在启动innodb的时候,不管上次是正常关闭还是异常关闭,总是会进行恢复操作。
因为redo log记录的是数据页的物理变化,因此恢复的时候速度比逻辑日志(如二进制日志)要快很多。而且,innodb自身也做了一定程度的优化,让恢复速度变得更快。
重启innodb时,checkpoint表示已经完整刷到磁盘上data page上的LSN,因此恢复时仅需要恢复从checkpoint开始的日志部分。例如,当数据库在上一次checkpoint的LSN为10000时宕机,且事务是已经提交过的状态。启动数据库时会检查磁盘中数据页的LSN,如果数据页的LSN小于日志中的LSN,则会从检查点开始恢复。
还有一种情况,在宕机前正处于checkpoint的刷盘过程,且数据页的刷盘进度超过了日志页的刷盘进度。这时候一宕机,数据页中记录的LSN就会大于日志页中的LSN,在重启的恢复过程中会检查到这一情况,这时超出日志进度的部分将不会重做,因为这本身就表示已经做过的事情,无需再重做。
另外,事务日志具有幂等性,所以多次操作得到同一结果的行为在日志中只记录一次。而二进制日志不具有幂等性,多次操作会全部记录下来,在恢复的时候会多次执行二进制日志中的记录,速度就慢得多。例如,某记录中id初始值为2,通过update将值设置为了3,后来又设置成了2,在事务日志中记录的将是无变化的页,根本无需恢复;而二进制会记录下两次update操作,恢复时也将执行这两次update操作,速度比事务日志恢复更慢。
checkpoint图例讲解
如果通过以上
LNS的理论讲解,若你还是没有看懂,没有关系,接下来,通过一个图例进行继续理解
静态检查点
现在有T1 、T2两个事务,则undolog中写入

这时到了检查点的周期,要往里写入检查点了,就得等到T1,T2全部提交完毕,然后写入检查点chkpoint。
也就是如果现在有一个T3要开启,是无法开启的。系统处于夯住状态。写入完后,开启T3,日志记录如下

这时候,如果系统挂掉了,故障恢复管理器会从undolog的尾部向前进行扫描,扫描到checkpoint后,就不会往前扫描了,因为前面的事务都已经提交过了,不存在数据一致性问题。所以只需要从checkpoint开始重做即可。
这样固然是好,省掉了需要undolog从头开始扫描的麻烦,但是这样做的缺点也很明显,那就是在写入checkpoint的过程中,系统是出于夯住状态的,所有的写入都要暂停。那能否有一种更好的方法既可以写入checkpoint又不需要系统暂停呢,必须的,当然有,这就是下面要讲的非静态检查点。
非静态检查点(重点)
非静态检查点是相对于静态检查点而来的,上文中所提到的就属于静态检查点,因为在检查点写入的同时,系统是不能写入的。而非静态检查点的引入,就是要解决这个问题。
非静态检查点的策略是在写入chkpoint的同时,会记录下当前活跃的事务。比如,当前状态下,T1和T2都是活跃状态,那么undolog中会被写入start checkpoint(T1,T2),这时整体系统仍然是正常写入的,也就是说在这条log写入后,仍然可以继续开启其他事务。当T1,T2完成后,会写入end checkpoint的记录。例如如下记录:

数据库宕机后Checkpoint定位恢复
第一种情况
数据库宕机后,恢复管理器仍然会从尾往前进行扫描undolog,如果遇到了“end chkpoint”,这时并不代表checkpoint前所有的事务都已经提交了,但我们可以知道,所有未提交的事务都是在上一个start checkpoint之后,所以会继续往前找,一直找到start checkpoint,找到start checkpoint后。
比如是start checkpoint(T1,T2),因为先前已经找到了end chkpoint,所以T1,T2这两个事务已经可以保证数据一致性了,需要重做的就是在start checpoint(T1,T2)到end chkpoint间的这一些非T1,T2事务,这些是需要重做的,所以要把这些进行重做。
另外一种情况
还有,就是恢复管理器在扫描时,先遇到了start checkpoint(T1,T2)的日志,在这种情况下,我们首先知道了T1,T2或许是未完成的事务,那这时需要在start checkpoint之后找到是否有某个事务的end语句,如果有,说明这个事务是完成了,如果没有,就说明没有完成,那就要从check point再往后寻找,找到这个事务的start,然后从start之后往后重做。说得比较罗嗦,我们上个例子来说明下这种情况。
例如,数据库宕机后,开始扫描undolog,得到以下片段:

这时,恢复管理器拿到这个片段后进行扫描,在遇到end chkpoint前遇到了start checkpoint(T1,T2),这说明了,T1,T2是可能未完成事务的,而且在这之前还遇到了T3的start,没有end T3,也没有任何T3的检查点的开始,这说明了T3一定是未完成事务的,所以T3一定是要重做的。
先前为什么说T1,T2是可能未完成事务的呢?
因为遇到了start checkpoint(T1,T2),没有遇到end chkpoint,并不代表T1和T2就一定是未完成的,可能有一个已经commit过了,因为两个都没有commit,所以才导致了没有end chkpoint,所以这时找start下面的日志,发现了“end T1”,说明了T1的事务是已经完成了的。
那只需要找T2的开启然后开始重做就可以了,然后就通过start checkpoint(T1,T2)再往上找,找到了start T2,然后开始重做T2,也就是这个日志里,T2和T3是需要重做的,然后重做掉。
Tips:
刚才先说了做T3,然后有说了重做T2,并不代表真正的顺序就是这样,实际上恢复管理器是先分析出需要重做的事务,然后通过buf一块做掉的。